您好!今天是:2025年-4月23日-星期三
生命是怎樣涌現的:系統生物學入門全路徑
點擊:7419 作者:Clover青子 來源:人工智能學家微信號 發布時間:2023-08-05 10:37:01

導語:系統生物學及相關跨學科領域正在興起,近年來基于各類疾病的組學研究成果頻出。作者整理了這份結合多門教材、多篇經典論文的學習路徑,供你入門參考。如果你希望入門系統生物學,請掃開頭二維碼或點擊文末“閱讀原文”,注冊集智斑圖,資料更完備的學習路徑等著你~
什么是系統生物學
系統生物學(Systems biology),是一個使用整體論(而非還原論)研究范式,整合不同學科、層次的信息以理解生物系統如何行使功能的學術領域,是分子生物學之后現代生物學的全新階段,包括表觀遺傳學、各種生物組學、合成生物學、生物信息學等細分領域。
它通過融合數學、物理、化學、生物、醫學、信息與計算科學等多學科方法,從一種全新的生物動力學視角出發對生命現象進行研究,包括分子、細胞、器官、生物有機體乃至環境等實體生物系統各個組成部分相互作用關系下的表型、功能和行為。因此它兼具生物學和信息科學的特點。
一般說來,生物信息以這樣的方向進行流動:DNA→mRNA→蛋白質→蛋白質相互作用網絡→細胞→器官→個體→群體。這里要注意的是,每個層次信息都對理解生命系統的運行提供有用的視角。不同層次的研究難度也是不一樣的。系統生物學的重要任務就是要盡可能地獲得每個層次的信息并將它們進行整合。

圖1:人體系統的不同層級,信息自上由下流動
生物有機體是非常復雜的,許多部分以多種方式相互作用,因此通常可以被看作是一個集成的系統。從這點看一個細胞信號網絡和一個收音機有很多相似之處[1]。但比之收音機,試圖理解一個生物有機體系統要困難得多,主要是因為系統中交互作用的數量和強度過于巨大且缺乏一種通用的生物學描述語言。不過,可用的計算機能力和復雜系統分析的進步帶來了希望,成為系統生物學的基本和不可缺少的方法。
論文題目:
Can a biologist fix a radio?—Or, what I learned while studying apoptosis
論文地址:https://doi.org/10.1007/s10541-005-0088-1
圖2:一個收音機的電路系統
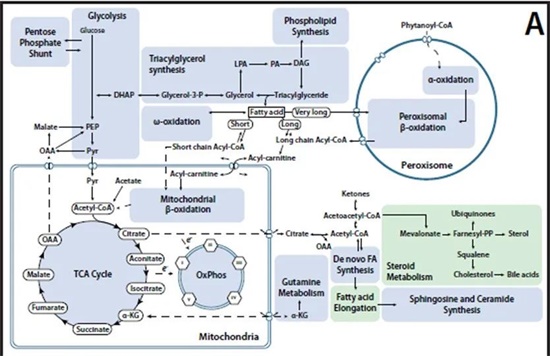
圖3:一個細胞的代謝系統
系統生物學不同于以往僅僅關心個別的基因和蛋白質的分子生物學,著眼于研究細胞信號傳導和基因調控網路、生物系統組成之間相互關系的結構和系統功能的涌現。系統生物學的目標之一就是模擬和發現涌現的特性,并期望最終能夠建立包括整個生物系統的可理解模型。
事實上,據 2011 年的《cell》報導,這一壯舉已經在生殖支原體(Mycoplasma genitalium)的細胞模型中實現了,其中所有的基因、產物以及已知的代謝相互作用都已在電腦中重建[2]。
論文題目:
A whole-cell computational model predicts phenotype from genotype論文地址:https://www.sciencedirect.com/science/article/pii/S0092867412007763
也許我們很快就會看到一個完整的多細胞生物的電腦模擬模型。盡管這對于數百萬到數萬億個細胞來說似乎是不可行的,但我們仍對科學的發展滿懷熱情,畢竟目前所取得的研究成果,10 年前在計算或技術上也曾被認為是不可能的。
系統生物學的歷史進程
1924-1928 年奧地利生物學家貝塔郎菲多次發表系統論的文章,闡述生物學中有機體概念,提出把有機體當作一個整體或系統來研究。貝塔朗菲的一般系統論,維納的控制論到香農的信息論,及普利高津的耗散結構理論(Dissipative structures),均將生命現象看作區別于僅靠外部指令運作的自組織系統。自 20 世紀 60 年代系統生物學概念和詞匯的提出起,60-80 年代系統生態學、系統生理學的進展,90 年代系統生物醫學、系統醫學、系統生物工程與系統遺傳學的概念發表,與 20 世紀未細胞信號傳導與基因調控的研究與系統論方法的結合后,系統生物學進入了分子細胞層次的(實驗與理論結合)研究與發展時期。尤其在 1979 年,德國生物化學家艾根提出超循環理論(Hypercycles),對無機分子自組織成生物大分子的可能機制進行了解釋,打通了生命系統和無機物之間的橋梁。21世紀,系統生物學的發展進入了細胞信號轉導與基因表達調控的細胞分子系統生物學時期,國際,國內的系統與合成生物學,系統遺傳學等研究機構紛紛建立,讓生物學進入了系統生命科學時代。2001 年的第二屆國際系統生物學會提出對生物體整個過程做全面性的定量研究,并希望利用計算機運算來預測細胞,器官系統甚至完整生物體的表現。
人類基因組計劃(HGP:Human Genome Project ; 1990–2003)的發起人之一,美國科學家萊諾伊·胡德 (Leroy Hood) 是組學 (Omics) 生物技術開創者之一。正是在基因組學(Genomics)、蛋白質組學(Proteomics)等新型大科學發展的基礎上,孕育了系統生物學種種高通量生物技術和生物信息技術。
研究的四個階段
1. 初步模型:
是對選定的某一生物系統的所有組分進行了解和確定,描繪出該系統的結構,包括基因相互作用網絡和代謝途徑,以及細胞內和細胞間的作用機理,以此構造出一個初步的系統模型。
2. 觀測實驗:
是系統地改變被研究對象的內部組成成分(如基因突變)或外部生長條件,然后觀測在這些情況下系統組分或結構所發生的相應變化,包括基因表達、蛋白質表達和相互作用、代謝途徑等的變化,并把得到的有關信息進行整合。
3. 分析修訂:
把通過實驗得到的數據與根據模型預測的情況進行比較,并對初始模型進行修訂。
4. 理想模型:
根據修正后的模型的預測或假設,設定和實施新的改變系統狀態的實驗,重復第二步和第三步,不斷地通過實驗數據對模型進行修訂和精練。第一到第三階段,也就是所謂的“整合”- 系統理論、“干涉”- 實驗生物學和“信息”- 計算生物學研究過程,即系統生物學通過系統論和實驗(Experimental)、計算(Computational)等概念和方法的整合,目標就是要得到一個理想的完整模型,使其理論預測能夠全面反映出生物系統的真實性。
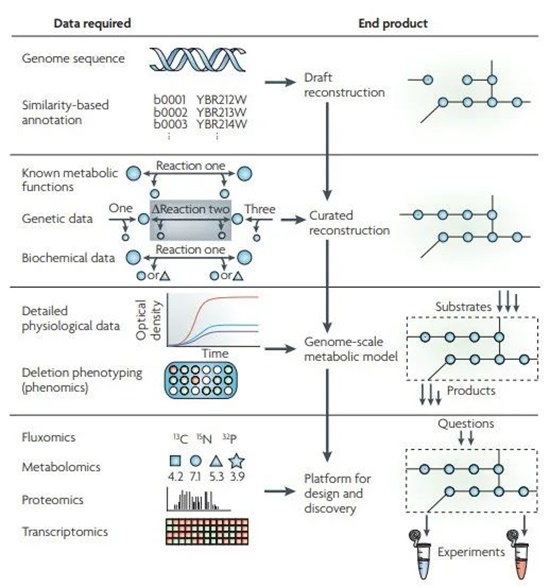
圖4:系統生物學重構代謝過程的四個階段
以上圖四個階段為例,每一個階段都是在前一個階段的基礎上建立起來的。重構過程的另一個特點是重構內容的迭代細化,這是由后三個階段的實驗數據驅動的。對于每個階段,都需要特定的數據類型,這些數據類型包括從高通量數據類型(例如,基因組學和代謝組學)到描述單個成分的詳細研究(例如,特定反應的生化數據)。每個重構階段生成的結果可以用于檢查越來越多的問題,最終獲得理想模型[3]。
論文題目:
Reconstruction of Biochemical Networks in Microorganisms論文地址:https://www.nature.com/articles/nrmicro1949
研究方法分類
“干涉”與“發現”的科學
1. 干涉
凡是實驗科學都有這樣一種特征:人為地設定某種或某些條件去作用于被實驗的對象,從而達到實驗的目的。這種對實驗對象的人為影響就是干涉 (Perturbation)。系統生物學中的干涉有這樣一些特點。首先,這些干涉應該是有系統性的。例如人為誘導基因突變,過去大多是隨機的;而在進行系統生物學研究時,應該采用的是定向的突變技術。
2. 發現
以測定基因組全序列或全部蛋白質組成的基因組研究或蛋白質組研究等“規模型大科學”,并不屬于經典的實驗科學。這類工作中并不需要干涉,其目標只是把系統的全部元素測定清楚,以便得到一個含有所有信息的數據庫。萊諾伊·胡德把這種類型的研究稱為“發現的科學” (Discovery Science),而把上述依賴于干涉的實驗科學稱為“假設驅動的科學” (Hypothesis-driven science),因為選擇干涉就是在做出假設。
“干”與“濕”實驗
離開了數學和計算機科學,就不會有系統生物學。也許正是基于這一考慮,科學家把系統生物學分為“濕”的實驗部分(實驗室內的研究)和“干”的實驗部分(計算機模擬和理論分析)。
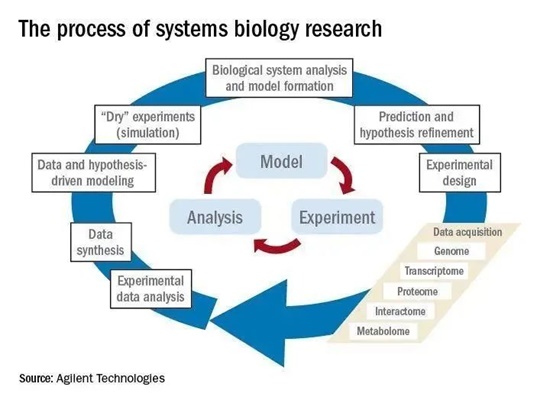
圖5:系統生物學包括“干”“濕”結合以不斷優化生物模型的研究過程
“自頂向下”與“自下而上”的方法
系統生物學的目的是在計算機模型(或數學模型)中重建一個生物系統,然后用來模擬系統的行為。基本上有兩種系統生物學的方法,“自頂向下”從全部組學分析開始,而“自下而上”是從已知的單個路徑開始,在實際應用中它們可以互補而不是相互排斥[4]。
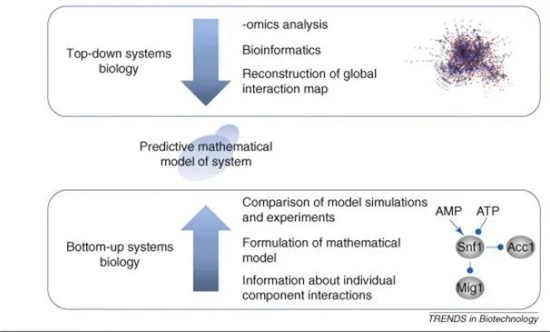
圖6:顯示不同的系統生物學手段:在自頂向下的系統生物學中,高通量的實驗數據,這些數據被用來重建通路或共調控模塊。這些模塊可以成為更詳細的研究的基礎,其中單個組件的動力學被量化。在自下而上的系統生物學中,通路的重建是基于對個體成分相互作用的研究。
1. 自頂向下
自頂向下的系統生物學(Top-down systems biology)依賴于不同的全基因組分析,在這種分析中,數據是從一個暴露在不同條件下或受到基因干擾(如通過敲除特定基因)的系統中收集的。首先,基因、蛋白質和代謝產物表現出顯著變化識別使用適當的統計方法(通常與多個校正測試),緊隨其后的是集群和更高級的分析,得到的數據可以結合結構信息,例如 DNA 的蛋白質相互作用數據(從CHIP-chip實驗)。這種類型的分析通常使識別協同調節模塊成為可能。自頂向下的系統生物學的優點是它是非教條的,并且不需要通路結構的先驗知識。由于假陽性的可能性,重構的通路需要用傳統的分子生物學進行實驗驗證。
2. 自下而上
自下而上的系統生物學(Bottom-up systems biology)依賴于已知路徑或子系統的可用知識。這種知識被組合成一個所謂的描述性模型的,并轉換成數學模型。該數學模型可用于模擬不同條件下的路徑運行。通過與實驗數據的比較,有可能估計系統或路徑內的個別過程的詳細動力學。在得到系統的可接受的數學表示之前,常常需要對模型進行修正;因此,需要與實驗工作密切配合,進行模型構建和仿真。所得模型可用于設計實驗,進一步驗證或證偽模型。這個過程的最終結果是一個動態數學模型,可以用來模擬所研究的生物系統。這種方法的缺點是,重建的模型高度依賴于當前已知系統通路的知識,尚未被識別成分的影響往往一開始完全被忽略掉。
教材推薦
以下推薦幾本教材面向的受眾是不同的,第一本適合入門,第二本和第三本則偏重哲學層面,第四本和第五本則更加偏向技術性。英文教材只有第五本有中譯版。部分英文書籍介紹里附有鏈接。
《系統生物學》
《Systems Biology: Philosophical Foundations》
《Life: An Introduction to Complex Systems Biology》
《Systems Biology: Properties of Reconstructed Networks 》
《An Introduction to Systems Biology: Design Principles of Biological Circuits》
1. 張自立編著的《系統生物學》是目前我國高校使用的教材。整合了各層面的生物信息數據,建立各種數學模型進行仿真實驗,進而定量闡明和預測生物功能、表型及行為。概述了系統生物學的基本概念和基本內容,介紹了基因組學(Genomics)、轉錄組學(Transcriptome)、蛋白質組學(Proteomics)、糖組學(Metabolomics)、代謝物組學(Metabolomics)、相互作用組學、表型組學、數學建模與仿真、序列比對與數據庫搜索、分子進化模型與系統樹的構建等。
2.《Systems Biology: Philosophical Foundations》是第一本關于系統生物學哲學基礎的書。代表了近年來在與系統生物學相關的一系列哲學問題上的研究成果。包含十四篇論文,分為三個部分。第一部分描述了系統生物學研究計劃(第2章和第5章),第二部分討論了理論和模型(第6章和第9章),第三部分討論了生物系統中的組織(第10章和第13章)。
全文下載鏈接:
https://www.sciencedirect.com/science/article/pii/B9780444520852500036?via%3Dihub#cesec1

圖7:《Systems Biology: Philosophical Foundations》封面
3.《Life: An Introduction to Complex Systems Biology》這本 2003 年由 kaneko 寫作的書,2006 年再版,本書一共有十二個章節,主要是面向年輕的生物學家和理論物理學家。這本提出的問題:什么是生命系統的通用屬性和一個人怎么從生命的的現象學理論構造導致自然生殖細胞等復雜過程系統、進化和分化?
第一章,回顧了分子生物學的研究現狀。對現狀提出批評,以及需要的是另一種方法,作者稱之為復雜系統生物學。在第2章中,作者概述了建構生物學的方法,即通過實驗(在實驗室中)和理論(在計算機模型中)構建生命的基本特征來理解它們。在第3章中,一些動力學系統和統計物理的基本背景被描述,作為在后面章節描述的研究的基礎。第4章至第11章中討論生命系統的基本問題。這些問題包括遺傳(第4章)、繁殖和新陳代謝(第5章和第6章)、細胞分化、發育和形態發生(第7章和第9章)、與生物可塑性有關的進化(第10章)和多樣化的物種形成(第11章)。在第12章中,總結了書中提出的基本概念,如穩定增長系統中的普遍統計、相應的多樣化、合并、流動和少數控制原則。然后討論如何理解生物的可塑性、遞歸性和進化性,同時強調現象學理論在生物學系統層面的必要性和可能性。
全文下載鏈接 :
https://link.springer.com/book/10.1007/978-3-540-32667-0

圖8:Kaneko《Life:An Introduction to Complex Systems Biology》封面
4. Palsson的《Systems Biology: Properties of Reconstructed Networks 》是更多從技術層面出發,以數學的方式表示化學計量矩陣,而這個矩陣的性質是決定它所代表的生化反應網絡的官能狀態的關鍵。這本教科書,致力于描述如何建模網絡,如何確定他們的性質,以及如何將這些與表型功能重建為詳細的,和可預測電路模型的生物系統。一些線性代數和生物化學的知識在閱讀之前必不可少。
5.《An Introduction to Systems Biology:Design Principles of Biological Circuits》首次對系統生物學研究工作的核心和細節進行深入闡述,為直觀理解生物學中一般原理建立了基礎。Alon 的書適合假定沒有生物學的知識,甚至對生物學不感興趣的物理學家。全書內容編排:對網絡模體等新的理論研究成果做了細致深入的闡述,指出了系統生物學的核心內容和實踐方法;闡明了轉錄調控、信號轉導、發育網絡中的基本回路;檢測了魯棒性原理;清晰地說明了如何用進化優化來理解最優回路設計;仔細考慮了動力學校正和其他機制是如何使生物信息處理中的誤差減到最少。
系統生物學經典文獻
貝塔朗菲:一般系統論
路德維希·馮·貝塔朗菲(Ludwig Von Bertalanffy,1901-1972)—美籍奧地利理論生物學家和哲學家;一般系統論的創始人,他從生物學領域出發,涉獵醫學、心理學、行為科學、歷史學、哲學等諸多學科,以其淵博的知識、濃厚的人文科學修養,創立了本世紀具有深遠意義的一般系統論,使他的名字永久地與系統理論聯系在一起。1972年,法國科學家委員會曾提名他為諾貝爾獎候選人,但是在諾貝爾獎評選委員會討論提名之前,貝塔朗菲不幸辭世。
1950年發表《物理學與生物學中的開放系統理論》創立一般系統論并奠定了系統生物學的基礎[5] [6]。我們可以看到,系統科學的研究和創立一開始就是和生物學息息相關的。
論文題目:
The Theory of Open Systems in Physics and Biology論文地址:https://science.sciencemag.org/content/111/2872/23/tab-pdf
論文題目:
An Outline of General System Theory (1950)論文地址:http://www.isnature.org/Events/2009/Summer/r/Bertalanffy1950-GST_Outline_SELECT.pdf
普利高津: 結構耗散理論
普利高津(Ilya Prigogine, 1917-2003)認為,只有在非平衡系統中,在與外界有著物質與能量的交換的情況下,系統內各要素存在復雜的非線性相干效應時才可能產生自組織現象,并且把這種條件下生成的自組織有序態稱之為耗散結構。一個對象要想在活動中獲得存在與發展,必須不斷地從外界引入負熵,以抵消系統體內正熵的增加,從而確保自身不斷地走向更高層次的穩定有序結構[7]。普利高津因此在 1977 獲得諾貝爾化學獎。
論文題目:
Thermodynamic Theory of Structure, Stability and Fluctuations.
論文地址:https://onlinelibrary.wiley.com/doi/abs/10.1002/bbpc.19720760520
艾根:超循環理論
艾根(Manfred Eigen,1927-2019),1967年獲得諾貝爾化學獎。超循環是一種自然自組織的原理,允許一組功能耦合的自代表實體的連續一致演化。超循環是一類新穎的非線性反應網絡,它是一個能夠自我指導自身復制的整體,并為下一個循環的復制提供了催化支持[8] [9]。如下圖所示,信息載體 I 不僅包含了自身復制的信息,還包含了具有促使轉化成其他類型所對應功能特性的媒介物 E(通常是一種酶)的信息。這種由載體信息生成的酶,支持了下一個信息載體的活性。一個超催化循環由若干網狀的催化循環形成,必須的兩種功能是,每個循環能夠自我復制,并且一個循環的產物必須支持下一個循環。

圖9:超循環是一種自我復制的大分子系統,其中 RNA(I)和酶(E)的協同作用。
論文題目:
Self organization of matter and the evolution of biological macromolecules
論文地址:https://link.springer.com/article/10.1007/BF00623322
論文題目:
The Hypercycle: A principle of natural self-organization
論文地址:https://onlinelibrary.wiley.com/doi/abs/10.1002/qua.560140722
胡德
作為人類基因組計劃的發起人之一,美國科學家萊諾伊·胡德(Leroy Hood)也是組學 (Omics) 生物技術開創者之一。胡德已經開發了突破性的科學儀器,使生物科學和醫學科學的重大進展成為可能。這些包括用于確定組成給定蛋白質的氨基酸的第一氣相蛋白質測序器,DNA 合成器,用來合成 DNA 的短片段,肽合成器,將氨基酸結合成較長的肽和較短的蛋白質,第一個自動DNA測序器[10] [11]。
論文題目:
The digital code of DNA論文地址:https://www.ncbi.nlm.nih.gov/pubmed/12540920
論文題目:
Systems Biology and New Technologies Enable Predictive and Preventative Medicine論文地址:https://api.semanticscholar.org/CorpusID:33015388
曾邦哲
1996 年在北京舉辦的第 1 屆國際轉基因動物學術研討會,中科院曾邦哲闡述了系統論與生物遺傳學、轉基因研究等,1999 年元月于德國建立了系統生物科學與工程網(http://www.sysbioeng.com/genozen/project.html)表述生物系統結構論(Structurity theory)的結構整合 (Integrative)、調適穩態(Stability)與層級建構(Constructive) 等綜合(Synthetic)系統理論規律,并定義實驗、計算系統研究,同系統科學、計算機科學、納米科學和生物醫學、生物工程等領域國際科學家廣泛通訊,倡導分子生物技術和計算機科學 -實驗生物學家與計算生物學家結合研究生物系統,喚起了一大批生物學研究領域以外的專家的關注。
北野宏明
1999 年更早的中期不少科學家開始了論述,2000 年日本舉辦了國際系統生物學會議,隨后,系統生物學便逐漸重新得到了生物科學界的認同。2002 年日本北野宏明(Kitano H.)也論述了系統生物學是實驗與計算方法整合的生物系統研究[12] [13]。
論文題目:
Computational systems biology論文地址:https://doi.org/10.1038/nature01254
論文標題:
The systems biology markup language (SBML): a medium for representation and exchange of biochemical network models論文地址:https://doi.org/10.1093/bioinformatics/btg015
2004 的綜述里闡述了生物系統的魯棒性:魯棒性是生物系統普遍存在的特性。它被認為是復雜演化系統的一個基本特征。它是通過對生物有機體和復雜工程系統普遍適用的幾個基本原則來實現的。魯棒性促進了可進化性,而魯棒性特征通常是由進化選擇的[14]。
論文題目:
Biological robustness論文地址:https://www.ncbi.nlm.nih.gov/pubmed/15520792
合成生物學
2000 年美國 E. Kool 基于系統生物學的基因工程,重新提出合成生物學(Synthetic biology)。
合成生物學是一門將科學與工程相結合,以設計和構建新的生物功能和系統的生物學研究新領域。合成生物學的定義已被普遍接受為生物學工程:綜合復雜的、基于生物學的(或啟發的)系統,這些系統顯示了自然界中不存在的功能。這種工程學的觀點可以應用于生物結構的各個層次,從單個分子到整個細胞、組織和生物體[15]。
專著題目:
Synthetic Biology, Volume 1專著地址:https://www.overdrive.com/media/2502000/synthetic-biology-volume-1
合成生物學家分為兩大類。一種使用非自然分子來重現自然生物學中出現的行為,目的是創造人工生命。另一種則從自然生物學中尋找可互換的部分,將其組合成非自然功能運行的系統[16]。
論文題目:
Synthetic Biology論文地址:http://dx.doi.org/10.1038/nrg1637
2008 年 Nature 文章則論述了系統生物學與合成生物學的結構理論[17]。
論文題目:
Systems and Synthetic biology: tackling genetic networks and complex diseases論文地址:https://www.nature.com/articles/hdy200918
生物信息學
生物信息學(Bioinformatics)包括開發和應用軟件工具,以幫助理解生物功能和數據,而系統生物學涉及數學和計算建模的生物系統和功能,以簡化表示,理解和文檔。生物信息學整合和應用統計學、數學、計算機科學、工程和生物學的理論和實踐知識,并允許在生物數據的電腦分析和計算機化解釋的數據。另一方面,系統生物學利用信號通路、代謝網絡和基因序列功能的知識,以促進科學的研究和應用。
生物信息學最早出現在 50 多年前,當時臺式電腦還只是一種假設,DNA 還無法測序。20 世紀 60 年代,第一個新的肽序列組裝器、第一個蛋白質序列數據庫和第一個用于系統發育的氨基酸替代模型被開發出來。在 20 世紀 70 年代和 80 年代,分子生物學和計算機科學的并行發展為分析全基因組等日益復雜的工作鋪平了道路。在 1990 年的 21 世紀頭十年,互聯網的使用,加上二代測序,導致了數據的指數增長和生物信息學工具的迅速發展。今天,生物信息學面臨著多種挑戰,如處理大數據、確保結果的再現性以及與學術領域的恰當交融[18]。
瑪格麗特·達霍夫(Margaret Dayhoff,1925-1983)是一位美國物理化學家,她率先將計算機方法應用于生物化學領域[19]。
論文題目:
Digital electronic computers in biomedical science.論文地址:https://www.ncbi.nlm.nih.gov/pubmed/14415153

圖10:NCBI 基因庫和 WGS(Whole Genome Shotgun,全基因組鳥槍法)數據庫中隨時間變化的序列總數。
在 1990 年代到 2000 年代,測序技術的重大改進以及成本的降低使數據呈指數級增長。自 2008 年以來,摩爾定律不再是 DNA 測序成本的準確預測指標,在大規模并行測序技術出現后,摩爾定律降低了幾個數量級。
雖然在某些情況下,根據必要的計算,一臺簡單的臺式計算機就足夠了,但生物信息學的一些項目將需要更龐大、昂貴和需要專門知識的基礎設施。一些政府資助的專門從事高性能計算的組織已經出現,例如:
Compute Canada (https://www.computecanada.ca)
New York State’s High Performance Computing Program
(https://esd.ny.gov/new-york-state-high-performance-computingprogram)
The European Technology Platform for High Performance Computing (http://www.etp4hpc.eu/)
China’s National Center for High-Performance Computing (http://www.nchc.org.tw/en/)
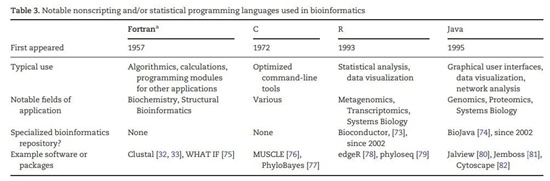
圖11:一些生物信息學中使用的非腳本和/或統計編程語言,以及應用軟件和程序包[18]。
Science 合集
2002 年03 月,美國《Science》周刊登載了系統生物學專集(鏈接:http://science.sciencemag.org/content/295/5560),該專集導論中的第一句話這樣寫道:“如果對當前流行的、前沿的關鍵詞進行一番分析,那么人們會發現,‘系統’高居在排行榜上。”專題中包含四篇綜述論文:

圖12:專題封面圖:以模塊化聞名的樂高積木,是對生物架構和動態過程一個恰當的比喻,包括從基因表達到組織和有機體的功能各個層次,組件之間的聯系、如何被管理的,以及它們是如何進化的。這些都是理解不同層次生物復雜性的關鍵。
第一篇是有北野宏明所作,闡述了從系統的層面理解生物學,我們必須研究細胞和有機體功能的結構和動態,而不是細胞或有機體的孤立部分的特征。系統的特性,如魯棒性,成為中心問題,了解這些特性可能會對醫學的未來產生影響。然而,在系統生物學的成就能夠發揮其備受吹捧的潛力之前,需要在實驗裝置、先進軟件和分析方法上取得許多突破[20]。
論文題目:
Systems Biology: A Brief Overview論文地址:https://science.sciencemag.org/content/295/5560/1662
第二篇綜述從工程理論和實踐中闡明一些生物復雜性的見解。先進的技術和生物學有著截然不同的物理實現,但它們在系統級組織方面的相似之處遠比人們普遍認為的要多。這兩個領域的趨同演化產生了由協議的精細層次結構和反饋調節層組成的模塊化架構,這些架構是由對不確定環境的魯棒性需求驅動的,并且經常使用不精確的組件。這些令人困惑和矛盾的特征既不是偶然的,也不是人為的,而是源于復雜性和魯棒性、模塊化、反饋和脆弱性之間深刻而必要的相互作用[21]。
論文題目:
Reverse Engineering of Biological Complexity論文地址:https://science.sciencemag.org/content/295/5560/1664
第三篇以海膽為例,闡述了胚胎內胚層和中胚層規格的基因調控網絡。該網絡是由大規模擾動分析,結合計算方法,基因組數據,順式調控分析,和分子胚胎學。該網絡目前包含 40 多個基因,每個節點都可以通過順式調控分析在 DNA 序列水平上直接驗證。其結構體系揭示了發育的具體和一般方面,例如特定的細胞如何在胚胎中產生它們指定的命運,以及為什么這一過程在發育過程中不可阻擋地向前發展[22]。
論文題目:
A Genomic Regulatory Network for Development論文地址:https://science.sciencemag.org/content/295/5560/1669
第四篇綜述以心臟這一器官為例,闡述了器官建模的進展。成功的生理分析需要理解細胞、器官和系統的關鍵組成部分之間的功能相互作用,以及這些相互作用在疾病狀態中是如何變化的。這些信息既不存在于基因組中,也不存在于基因編碼的單個蛋白質中。它存在于亞細胞、細胞、組織、器官和系統結構中蛋白質相互作用的水平。因此,除了復制自然和計算這些交互來確定健康和病理狀態的邏輯之外,沒有其他選擇。生物數據庫的迅速增長;細胞、組織和器官模型;而強大的計算硬件和算法的發展使得從基因到整個器官和調節系統的生理功能的定量探索功能成為可能[23]。
論文題目:
Modeling the Heart--from Genes to Cells to the Whole Organ論文地址:https://science.sciencemag.org/content/295/5560/1678
相關領域前沿文章
根據使用跨學科工具從多個實驗中獲得,整合和分析復雜數據集的能力的系統生物學解釋,一些典型的技術平臺包括:基因組學,表觀遺傳組,轉錄組學,蛋白質組學,代謝物組學,糖組學,脂類組學(Lipomics),除了上述給定分子的識別和量化之外,進一步的技術還分析細胞內的動力學和相互作用。包括:相互作用組學(Interactomics),代謝流組學(Fluxomics),生物組學(Biomics)。其他技術如計算機科學,信息學和統計學的其他方面也用于系統生物學。

圖13:多組學方法對某種特定疾病的研究。組學數據收集在整個分子池上,以圓圈表示。除了基因組外,所有的數據層都同時反映了遺傳調控和環境,這可能會對每個個體分子產生不同程度的影響。細黑箭頭表示在不同層中檢測到的分子之間潛在的相互作用或相關性。例如,紅色的轉錄本可以與多種蛋白質相關聯。在同一層中,交互也很普遍,圖中未表述[24]。
漢族人全基因組
為了獲得全面、獨立、高質量的中國人群特異性基因組數據庫,中國代謝解析計劃ChinaMAP(China Metabolic Analytics Project)誕生了。4月30日,ChinaMAP在《Cell Research》雜志上發表了一期研究成果,首次報道了來自全國 27 個省份和直轄市、8個民族超過一萬人的深度全基因組測序數據分析,發現了 1.36 億個單核苷酸多態性(SNPs)和 1070 萬個插入或缺失位點(INDEL),其中一半以上是未在其他數據庫報道過的新突變[25]。
論文題目:
The ChinaMAP analytics of deep whole genome sequences in 10,588 individuals
論文地址:https://doi.org/10.1038/s41422-020-0322-9
古DNA組重建人類歷史
該文系首次正式發表大規模東亞南北方史前人類基因組分析結果,為探源華夏族群及其文化和修正東亞南方人群演化模式做出了重大貢獻。在中華民族探源方面,發現中國、東亞主體人群連續演化是主旋律,中國南北方古人群早在 9500 年前已經分化,至少在 8300 年前南北人群融合與文化交流的進程即已開始,4800 年前出現強化趨勢,至今仍在延續[26]。
論文題目:
American Association for the Advancement of Science論文地址:https://www.britannica.com/topic/American-Association-for-the-Advancement-of-Science
泛癌癥全基因組(Pan-cancer Genomics)
Nature 雜志2020年2月份整理了數篇全基因組的泛癌癥分析的文章(鏈接:https://www.nature.com/collections/afdejfafdb)。
癌癥是一種基因組疾病,由細胞獲得關鍵癌癥基因的體細胞突變引起。這些突變改變了調節細胞生長和與組織環境相互作用的途徑。直到最近,對癌癥基因組的研究都集中在蛋白質編碼基因上,這些基因加起來只占基因組的 1%。為了解決這個問題, ICGC/TCGA 全基因組癌癥分析(PCAWG)項目對超過 2600 種原發癌癥及其 38 種不同腫瘤類型的正常組織進行了全基因組測序和綜合分析。這項研究揭示了廣泛的大規模結構性突變在癌癥所扮演的角色,確定這種癌癥相關的突變基因調控區域,推測腫瘤進化多個癌癥類型,照亮了體細胞突變和轉錄組之間的相互作用和研究生殖系遺傳變異的作用在調節突變過程[27] [28] [29]。
論文題目:
Pan-cancer analysis of whole genomes論文地址:https://www.nature.com/articles/s41586-020-1969-6
論文題目:
Patterns of somatic structural variation in human cancer genomes論文地址:https://doi.org/10.1038/s41586-019-1913-9
論文題目:
Analyses of non-coding somatic drivers in 2,658 cancer whole genomes論文地址:https://doi.org/10.1038/s41586-020-1965-x
TCGA數據庫
2020年5月11日,哈佛醫學院的 Andrew D. Cherniack 和 Rameen Beroukhim 合作發表文章Comprehensive Analysis of Genetic Ancestry and Its Molecular Correlates in Cancer,通過分析 TCGA 數據庫的 33 種癌癥類型的 10678 名病患的突變速率、DNA甲基化、mRNA 和 miRNA 表達,鑒定出與癌癥相關的遺傳性祖先因素(Ancestry effect)[30]。
論文題目:
Comprehensive Analysis of Genetic Ancestry and Its Molecular Correlates in Cancer, Cancer Genome Atlas Analysis Network
論文地址:https://pubmed.ncbi.nlm.nih.gov/32396860/
TCGA (The Cancer Genome Atlas)數據庫 https://portal.gdc.cancer.gov/ ,癌癥基因組圖譜(TCGA)是一個具有里程碑意義的癌癥基因組學項目,它對 20000 多例原發性癌癥進行了分子特征分析,并對 33 種癌癥類型的正常樣本進行了匹配。國家癌癥研究所和國家人類基因組研究所的這項聯合工程始于 2006 年,匯集了來自不同學科和不同機構的研究人員。
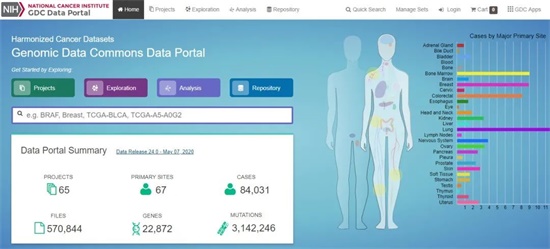
圖14:TCGA 數據庫首頁,可以根據感興趣的癌癥或者基因名進行檢索分析
癌癥信號通路圖譜
癌癥系統生物學的一個關鍵目標是利用大數據來闡明癌癥發生的分子網絡。但是,到目前為止,還沒有系統地評價這些努力取得了多大進展。下文中作者調查了六種主要的系統生物學方法,以繪制和建模癌癥路徑,并注意到他們的網絡地圖覆蓋和增強現有的知識[31]。
論文題目:
A census of pathway maps in cancer systems biology論文地址:https://doi.org/10.1038/s41568-020-0240-7
表觀遺傳組(Epigenomics)
2019年7月10日,來自美國 NIH 的 Ananda L. Roy 團隊回顧了 NIH 表觀遺傳組學藍圖計劃(Roadmap)啟動的契機和總體目標;介紹了表觀遺傳組學項目的成果:參考表觀遺傳組、國際間表觀遺傳的合作研究、疾病的表觀遺傳基礎和新型表觀遺傳標志物的發現、表觀遺傳研究技術的發展等;總結了項目實行過程中的經驗和教訓[32]。
論文題目:
The NIH Common Fund/Roadmap Epigenomics Program: Successes of a comprehensive consortium論文地址:https://doi.org/10.1126/sciadv.aaw6507
蛋白組 (Proteomics)
人類 SRMAtlas:代表人類蛋白質組的 166174 個蛋白型肽,提供了多種獨立的分析方法來量化任何人類蛋白和大量的剪接變異、非同義突變和翻譯后修飾[33]。本文通訊作者為 Hood L。
論文題目:
Human SRMAtlas:A Resource of Targeted Assays to Quantify the Complete Human Proteome論文地址:https://www.sciencedirect.com/science/article/pii/S0092867416308492
2020年4月,Nature 發表了一篇文章介紹了一個是一種系統的全蛋白質參考平臺:HuRI,它將基因組變異與表型結果聯系起來。一個包含約 53000 個蛋白質與 8000 多個蛋白質相互作用的人類二元蛋白質相互作用圖,為研究健康和疾病中的人類細胞功能提供了參考。推測的組織特異性網絡揭示了細胞環境特異性功能形成的一般原則,并闡明可能構成孟德爾疾病組織特異性表型的潛在分子機制[34]。
論文題目:
A reference map of the human binary protein interactome論文地址:https://www.nature.com/articles/s41586-020-2188-x
微生物組(Microbiome)
許多棲息在人體的微生物與人類的健康和疾病密切相關,但大部分微生物對我們而言仍然是未知的。美國國立衛生研究院(NIH)人體微生物組項目的研究人員已經確定,僅人體腸道微生物組就有 100 萬億細菌,是人體細胞數量的 10 倍。此外,它還含有大約 800 萬個蛋白質編碼基因,是人類基因組的 360 倍。科學家們已經了解到,這些細菌組成的變化——生態系統中的一種干擾——可能與一系列人類疾病有關,包括炎癥性腸病、哮喘、關節炎和多發性硬化癥[35]。
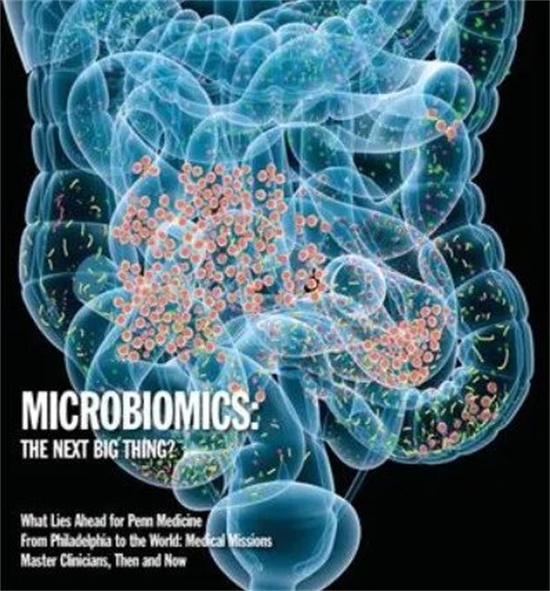
圖15:繼人類基因組計劃之后,美國國立衛生研究院在2007年啟動了一個類似的雄心勃勃的計劃——人類微生物組計劃(Human Microbiome Project,HMP),https://www.hmpdacc.org/。
論文題目:
Tackling the Microbiome論文地址:https://science.sciencemag.org/content/336/6086/1209
意大利特倫托大學的一支研究團隊展開一項超大規模研究,樣本涵蓋了不同地理位置、年齡和生活方式的人群以及人體的不同部位。他們利用單樣本宏基因組組裝,構建出超過 15 萬個人體微生物基因組,其中 77% 以前從未被描述過,確定了一些普遍存在、但以前未被發現的微生物類群[36]。
論文題目:
Extensive Unexplored Human Microbiome Diversity Revealed by Over 150,000 Genomes from Metagenomes Spanning Age, Geography, and Lifestyle論文地址:https://doi.org/10.1016/j.cell.2019.01.001
技術與工具
作為 ICGC/TCGA 全基因組泛癌分析(PCAWG)聯盟的一部分,作者訓練了一個深度學習分類器,以基于全基因組測序(WGS)中檢測到的代表 PCAWG 聯盟產生的 24 種常見癌癥類型的 2606 種腫瘤的體細胞旅客突變模式來預測癌癥類型。分類器在切除腫瘤樣本上的準確率分別為 91%,在獨立原發和轉移樣本上的準確率分別為 88% 和 83%,大約是訓練過的病理學家在不了解原發樣本的情況下對轉移腫瘤的準確率的兩倍[37]。
論文題目:
A deep learning system accurately classifies primary and metastatic cancers using passenger mutation patterns
論文地址:https://www.nature.com/articles/s41467-019-13825-8
理解復雜的生物系統需要軟件工具的廣泛支持。系統生物學計算工作流程的每一步都需要這些工具,通常包括數據處理、網絡推理、深度篩選、動態模擬和模型分析。此外,現在正在努力開發集成的軟件平臺,以便在工作流程的不同階段以及由不同的研究人員使用的工具可以很容易地一起使用。這篇綜述描述了在系統生物學研究的不同階段所需要的軟件工具的類型,以及目前可供系統生物學研究人員使用的選擇[38]。
論文題目:
Software for systems biology: from tools to integrated platforms論文地址:https://doi.org/10.1038/nrg3096
參考文獻:略
本文首發于集智斑圖:
https://pattern.swarma.org/path?id=67&from=wechat
文章來源于集智俱樂部 ,作者Clover青子
責任編輯:向太陽
特別申明:
1、本文只代表作者個人觀點,不代表本站觀點,僅供大家學習參考;
2、本站屬于非營利性網站,如涉及版權和名譽問題,請及時與本站聯系,我們將及時做相應處理;
3、歡迎各位網友光臨閱覽,文明上網,依法守規,IP可查。
作者 相關信息
內容 相關信息
事態緊急!專家和教授打起來了!生物學家饒毅炮轟網紅醫生張文宏散布謠言誤導大眾!
2022-12-22? 昆侖專題 ?
? 高端精神 ?

? 新征程 新任務 新前景 ?

? 習近平治國理政 理論與實踐 ?

? 國策建言 ?

? 國資國企改革 ?

? 雄安新區建設 ?

? 黨要管黨 從嚴治黨 ?

熱點排行



建言點贊



圖片新聞













