您好!今天是:2025年-4月20日-星期日
理解數據源是數據集成和治理的基礎
點擊:1490 作者:數據集成與治理 來源:數據集成與治理微信號 發布時間:2024-10-05 13:36:52
在數據集成和治理的復雜世界中,一個關鍵基礎的概念常常被忽視:數據源。數據源是數據集成和治理的基石,如果沒有對數據源的深刻理解,任何數據項目都可能在基礎不穩固的情況下開始,從而導致效率低下、成本增加,甚至項目失敗。在這篇文章中,我們將深入探討數據源,并闡釋它如何成為數據集成和治理成功的決定性因素。我們首先需要明確數據源是什么?有哪些類型?
數據源定義和類型
首先我們來了解下數據源的定義。數據源是指可用于分析、報告或數據處理的數據來源,它們可以是內部的,如公司數據庫,也可以是外部的,如公共數據集或API。
數據源的分類方法多樣,可以按照數據的來源、數據類型、更新方式等進行分類。例如,按數據來源分,數據可以是埋點行為數據、業務數據、日志數據或外部接入數據。
1、埋點數據通常來源于用戶與應用程序的交互行為,如點擊、滾動和表單提交等。
2、業務數據直接關聯到企業的核心運營活動,如銷售、財務和客戶關系管理等。這些數據通常存儲在關系型數據庫中,并且是結構化的
3、日志數據記錄了系統操作和事件的詳細信息,包括用戶行為、系統錯誤和性能指標等。日志數據對于監控系統健康、安全審計和故障排查非常重要。
4、外部數據源提供了組織外部的信息,如市場數據、社交媒體數據和第三方API數據

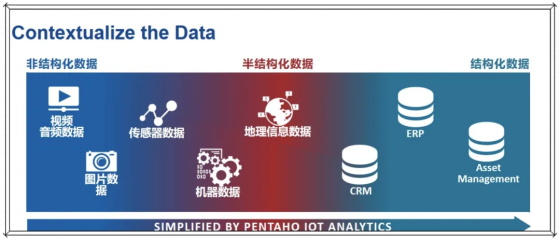
按數據類型分,可以分為結構化數據、半結構化數據和非結構化數據。
1、結構化數據(Structured Data)結構化數據是高度組織化的數據,通常存儲在關系型數據庫(如MySQL、Oracle、SQL Server等)中。這些數據遵循預定義的格式,可以通過行和列的形式來組織和存儲。
特點:數據字段明確:每個數據項都有明確定義的字段和類型,如日期、數字、字符串等。查詢效率高:由于數據結構固定,數據庫查詢優化得當,可以快速進行數據檢索。易于處理:結構化數據易于使用SQL等查詢語言進行處理和分析。
2、半結構化數據(Semi-structured Data)半結構化數據是介于完全結構化和完全非結構化之間的數據。它包含一些標記或域,但不像結構化數據那樣有嚴格的表格結構。常見的半結構化數據格式包括XML、JSON、CSV等。
特點:格式靈活:數據格式不固定,可以靈活地添加或刪除數據字段。易于擴展:可以方便地添加新的數據字段,適應不斷變化的數據需求。處理復雜:由于缺乏固定的結構,處理半結構化數據通常比處理結構化數據更復雜。
3、非結構化數據(Unstructured Data)非結構化數據是沒有固定格式或結構的數據。它不遵循預定義的數據模型,包括文本、圖像、視頻、音頻等。
特點:格式多樣:包括各種文件格式和媒體類型,如Word文檔、PDF、JPEG圖片、MP3音頻等。處理難度大:由于缺乏統一的結構,非結構化數據難以用傳統的數據庫查詢語言進行處理。信息豐富:非結構化數據通常包含大量的信息,但需要復雜的分析技術來提取價值。示例:電子郵件、社交媒體帖子、博客文章、圖片、視頻等。
在實際應用中,結構化數據通常用于需要精確查詢和分析的場景,而非結構化數據則更多地用于內容存儲和多媒體應用。半結構化數據則介于兩者之間,提供了一定的靈活性,同時也保持了一定的結構性,適用于需要快速變化和擴展的數據場景。
按更新方式分,可以分為批量數據和實時數據。
1、批量數據:是指累積到一定量后,一次性進行處理的數據。這種數據通常按照預定的時間間隔進行收集,比如每天、每周或每月。特點:延遲性:批量數據處理存在一定的時間延遲,因為數據需要積累到一定量才會處理。高吞吐量:由于是集中處理,批量數據處理可以優化資源使用,處理大量數據時效率較高。成本效益:對于不需要即時處理的數據,批量處理可以節省計算資源和成本。
2、實時數據是指數據生成后立即被處理和分析的數據。這種數據的處理通常是連續的,對時間敏感。特點:即時性:實時數據能夠提供最新的信息,對于需要快速響應的業務場景至關重要。動態性:實時數據處理能夠捕捉到數據的即時變化,支持動態決策。復雜性:實時數據的收集和處理通常更復雜,需要更先進的技術和工具。
訪問數據源
明確數據源后,根據不同的數據源類型選擇合適訪問方式,以下是訪問數據源的步驟:
1、確定數據源類型---對于數據庫,這可能包括服務器地址、端口號、數據庫名稱等
2、獲取訪問權限
3、使用合適的工具和API
·對于關系型數據庫,可以使用SQL客戶端或編程語言中的數據庫驅動(如 JDBC、PDO、Entity Framework等)。
·對于API,可以使用HTTP客戶端或專門的API客戶端庫。
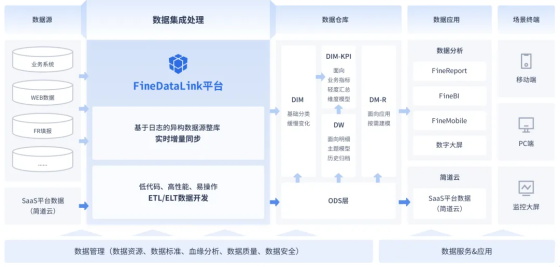
·選擇ETL工具對數據源進行讀取,如FineDataLink一站式數據集成平臺,可以讀取多種數據源。
4、建立連接
5、測試連接
6、進行數據源取數操作
理解數據源的注意事項
在大致掌握了數據源的知識后,我們來理解下數據源的關鍵性作用,尤其是需要理解數據源管理的作用。
1、確定數據集成需求,確保后續數據集成策略和業務目標一致
2、選擇合適的工具和技術,對確保數據集成的成功至關重要,同時正確的工具可以提高效率,減少錯誤
3、優化數據抽取過程,數據抽取是數據集成的核心環節,優化這一過程可以減少時間延遲,提高數據處理的速度和效率
4、提高數據質量:數據集成過程中可能需要對數據源中的數據進行清洗和驗證,以確保數據的一致性和準確性。
5、支持數據治理:數據源的元數據(如數據的來源、所有權、使用權限等)對于數據治理至關重要。了解這些信息有助于建立數據治理框架,確保數據的合理使用和管理。
6、數據源管理利于數據集成和處理:能夠確保數據的準確性、完整性和可靠性。保護數據確保符合法 律法規和公司政策;同時通過有效的數據源管理提高數據操作和管理的效率。
總之,深入理解數據源對于確保數據集成和處理的成功至關重要,它有助于構建有效的數據集成策略,提高數據的價值,并支持組織的業務目標。
FineDataLink---一站式數據集成和處理平臺,支持配置多種數據源,如Oracle, ClickHouse, Presto等數據源,同時在數據同步任務支持寫入和輸出多種數據源, 賦予用戶僅通過單一平臺,即可實現實時數據傳輸、數據調度、數據治理等各類復雜組合場景的能力,為企業業務的數字化轉型提供支持。賦予用戶僅通過單一平臺,即可實現實時數據傳輸、數據調度、數據治理等各類復雜組合場景的能力,為企業業務的數字化轉型提供支持。
來源:數據集成與治理微信號
責任編輯:向太陽
特別申明:
1、本文只代表作者個人觀點,不代表本站觀點,僅供大家學習參考;
2、本站屬于非營利性網站,如涉及版權和名譽問題,請及時與本站聯系,我們將及時做相應處理;
3、歡迎各位網友光臨閱覽,文明上網,依法守規,IP可查。
作者 相關信息
內容 相關信息
? 昆侖專題 ?
? 高端精神 ?

? 新征程 新任務 新前景 ?

? 習近平治國理政 理論與實踐 ?

? 國策建言 ?

? 國資國企改革 ?

? 雄安新區建設 ?

? 黨要管黨 從嚴治黨 ?

熱點排行



建言點贊


