您好!今天是:2025年-6月5日-星期四
胡錫進:硅谷驚恐了!中國AI大模型突然彎道超車
點擊:43812 作者:胡錫進 來源:胡錫進今日頭條號 發(fā)布時間:2025-01-27 10:43:08
人工智能是美國發(fā)誓要確保領先中國一大步的領域,也是美國極力試圖鎖住中國進步的前線。所以開年的1月20日,中國的AI公司推出全新的DeepSeek開源模型,讓美方的AI觀察家們幾近“破防”。“中國的人工智能越來越好,而且更便宜”,這是他們的驚呼。一個據(jù)稱是Meta員工發(fā)的帖子寫道:“DeepSeek最近的一系列動作讓Meta的生成式AI團隊陷入了恐慌。”因為在前者的低成本高歌猛進之下,后者無法解釋自己超高預算的合理性。
去年12月,這家名為“深度求索”的中國公司推出DeepSeek-V3,在全球AI領域已經(jīng)引起震動。它的訓練成本極低,甚至不到美國最先進GPT-4o訓練成本的二十分之一,但是性能卻可與之同處第一梯隊。今年1月DeepSeek推出的R1模型更是獲得了業(yè)內人士的認可,甚至被認為在推理和數(shù)學等領域比美國的大模型更加優(yōu)秀。
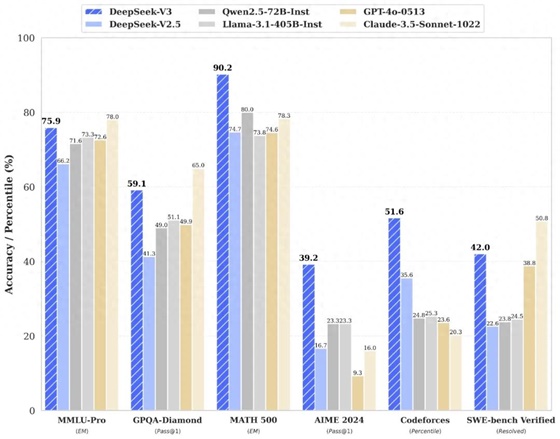
▲Deepseek-V3與多個國內外大模型的測試數(shù)據(jù)對比。(圖源:“Deepseek”公眾號)
尤其讓美國AI觀察家們詫異并且感到沮喪的是,以往為了阻止中國在人工智能領域的發(fā)展,美國政府一直在嚴格限制對中國出口高算力芯片,甚至不斷加強努力,防止中國通過第三方獲得先進芯片。DeepSeek僅僅用了英偉達為配合出口管制為中國市場量身定制的“閹割版”H800 GPU,但神奇的事情發(fā)生了,它們組合出的效果不亞于使用高性能芯片“卷算力”的美國大模型,而且因為它是完全開源的,專業(yè)人士可以清晰觀察DeepSeek是如何用更有效率的訓練方式與細膩的技術手段揚長避短的。
這些也是那名Meta員工“破防”的原因:使用了高算力H100 GPU的Meta Llama 3系列模型,其計算量足可訓練DeepSeek-V3至少15次,但是最終表現(xiàn)卻不及DeepSeek。美國《財富》雜志毫不掩飾地嘲諷道:美國剛剛承諾投入數(shù)千億美元來捍衛(wèi)其人工智能領導地位,一家“預算低得可笑”的中國初創(chuàng)公司可能已經(jīng)破壞了這些希望。
DeepSeek的大膽創(chuàng)新震驚了業(yè)內,雖然限于硬件設施以及成本投入等原因,它與美國的先進AI大模型比起來還有點“偏科”,但是卻給AI行業(yè)帶來了不少深度思考,它似乎在開創(chuàng)一條AI發(fā)展另辟蹊徑的可能路線。

▲扎克伯格2024年7月表示,開源是AI未來的方向,美國要領先中國AI數(shù)年的目標不現(xiàn)實。(圖源:上觀新聞)
大家知道,AI大模型領域的三大要素是算法、數(shù)據(jù)和算力。算力如同人大腦的神經(jīng)元,一個成熟的大模型需要訓練,理論上說,基礎算力越大,大模型就應該越聰明。所以美國各團隊之間形成了對基礎算力無窮無盡的追求和比拼。馬斯克旗下xAI的超級計算數(shù)據(jù)中心裝配了10萬顆英偉達H100 GPU芯片,堪稱當今世界最強大的AI訓練集群之一 。OpenAI創(chuàng)始人奧特曼也不甘示弱,表示將投入1000億美金,在得州建設10座數(shù)據(jù)中心,未來4年還要耗資5000億美金在全美打造20個超算集群。人們形成了一個印象:誰的GPU芯片集群大,誰就將穩(wěn)操勝券。
然而有一種可能是,基礎算力的無窮堆積不排除是階段性浪費,這種浪費不僅是芯片的過量使用,還有對電力的過量消耗,AI沿著這個路線狂奔,前方究竟是什么,是否存在陷阱和彎路,都是未知數(shù)。一個實際情況是,人類的現(xiàn)實需求是有限的,而且是獨特的,基礎算力應當與算法、數(shù)據(jù)形成最佳組合,而實現(xiàn)這樣的最優(yōu)解,是真正的考驗。
DeepSeek的意義在于它沒有跟著美國AI公司帶動的潮流“卷算力”,它也卷不動,但它卻在創(chuàng)造組合的最優(yōu)解方向做出大手筆開拓。換句話說,它以極低成本打開了AI探索的一個新方向,展示了新的可能性,在具體落地實現(xiàn)和理論創(chuàng)新之間找到了一個平衡路徑。DeepSeek 大模型的訓練成本僅557萬美元,價格僅有GPT-4的1%,無論是這樣的低成本還是注重細節(jié)的技術,都更契合先進科技一邊服務現(xiàn)實,一邊滾動發(fā)展的普世邏輯。

▲在2025年達沃斯論壇上,AI科技初創(chuàng)公司Scale AI創(chuàng)始人亞歷山大·王(Alexandr Wang)公開表示,中國人工智能公司DeepSeek的AI大模型性能大致與美國最好的模型相當。(圖源:第一財經(jīng))
DeepSeek的出現(xiàn)有可能帶動一波有規(guī)模的仿效,成為算法創(chuàng)新的催化劑。前Open AI聯(lián)合創(chuàng)始人、Tesla AI團隊負責人安德烈·卡帕西在社交平臺上發(fā)文稱,DeepSeek-V3的出現(xiàn)也許意味著不需要大型GPU集群來訓練前沿的大語言模型。還有人表示“如果DeepSeek的創(chuàng)新是真的,那AI公司是否真的需要那么多顯卡?”
Axios認為,美國限制高端人工智能半導體和技術向中國流動的政策可能有助于美國在人工智能性能曲線的外圍保持領先地位,但這也加速了中國更有效地構建高端人工智能的進程。是啊,中國這樣已經(jīng)有了雄厚科技資源儲備的國家是不可能被真正壓制的,美國從一個方向制裁,只會刺激中國更全面、更有韌性的進步,甚至“彎道超車”。美國的“小院高墻”最終困住的是誰,還說不清呢。
來源:胡錫進今日頭條號
責任編輯:向太陽
特別申明:
1、本文只代表作者個人觀點,不代表本站觀點,僅供大家學習參考;
2、本站屬于非營利性網(wǎng)站,如涉及版權和名譽問題,請及時與本站聯(lián)系,我們將及時做相應處理;
3、歡迎各位網(wǎng)友光臨閱覽,文明上網(wǎng),依法守規(guī),IP可查。
內容 相關信息
? 昆侖專題 ?
? 高端精神 ?

? 新征程 新任務 新前景 ?

? 習近平治國理政 理論與實踐 ?

? 國策建言 ?

? 國資國企改革 ?

? 雄安新區(qū)建設 ?

? 黨要管黨 從嚴治黨 ?

熱點排行
 老朱猜對了——安東尼·福奇的雙重身份
老朱猜對了——安東尼·福奇的雙重身份

建言點贊


? 社會調查 ?